
Why Observability Is Essential for AI Products
How monitoring key signals within an AI system helps detect failures, optimize performance, and maintain reliability in production


AI solutions don’t always behave as we expect, but the bigger problem is that it’s not always obvious when something has gone wrong. These systems can create a compelling illusion of quality. Even when the outputs are genuinely good, the underlying process could still have issues and inefficiencies.
Traditional monitoring can’t provide sufficient insight into the system’s behavior. Product builders have to use AI observability tools to capture detailed information about the system’s internal operations. These tools allow us to verify whether solutions are actually working as intended.
Observability is essential for making AI solutions reliable. It helps us inspect both the results and the process much more effectively, so we can make the right fixes, improvements, and optimizations. Without it, we’re just hoping nothing goes wrong, since everything looks fine on the surface.
What Is AI Observability?
AI observability is the process of monitoring AI systems by tracking key signals related to their behavior, performance, and reliability. It involves collecting, analyzing, and correlating these signals (also referred to as telemetry data) to understand how the system operates. We integrate observability tools (e.g., LangSmith, Langfuse, Helicone) into our AI system to record specific system interactions. This data can help us understand how specific changes impact the system’s performance. For example, it can quantify the impact of switching models (e.g., on token spend, output quality, or latency), helping us assess the tradeoffs of each one.
Why traditional monitoring falls short.
Traditional monitoring is designed for traditional software. Since all operations follow deterministic paths, for the most part, tracing the relationship between inputs and outputs is relatively straightforward. However, AI systems are non-deterministic: the same input could produce different outputs. This variability means there’s always a risk of something going wrong, no matter how well-designed the system is. Standard monitoring makes it difficult to trace the exact root cause of a bad output. It just doesn’t give us enough visibility into what specifically went wrong because the necessary data isn’t captured.
What Are The Main AI Observability Components
Logs
Logs are detailed, time-stamped records of application events. They can be used to create a high-fidelity, millisecond-by-millisecond record of every event within an AI system, along with the surrounding context. They are useful for investigating specific issues. For example, when investigating a failed request, we can use data from event logs (e.g., user interaction logs, model logs, tool use logs, etc.). This could help us examine the user’s query, the model’s interpretation of the user’s intent, and the specific actions executed, so we can diagnose the root cause.
Traces
Traces are end-to-end records of a request from user input to output. They are a key component of AI observability, since we add specific code to our system to generate these traces. While logs provide insight into specific interactions, traces help us understand the full sequence of interactions leading up to the final response. For example, when a user interacts with an agent, here’s what the trace might include: the user input, the agent’s plan and task breakdown, the agent’s tool calls, the model’s generated output, and the response returned to the user. When something goes wrong, the trace can help developers pinpoint the exact step where fixes are needed.
Metrics
Metrics are quantitative indicators of the AI system’s overall health and performance. They help us track specific deviations. For example, a huge spike in token consumption will increase inference costs, potentially leading to significantly higher AI bills. We use metrics to track when certain thresholds are exceeded, so we can take the necessary actions (e.g., changing usage limits or switching to cheaper models).
We need to track several key metrics in an AI system:
Inference latency metrics track how long the system takes to respond to requests. Long response times negatively impact the user experience, so tracking latency is critical for identifying issues that may be slowing down performance.
Request failure metrics track how often different requests fail (e.g., model requests, tool use requests, API requests). High failure rates in certain steps may indicate a need to either redesign specific components, switch to different providers, or implement fallbacks.
Response quality metrics assess the accuracy, consistency, completeness, relevance, and overall quality of the system’s outputs. Domain expertise is typically necessary to properly evaluate this data. Automated checks can only score approximate quality, but they can’t tell us whether an output was actually correct.
Token consumption metrics track how many tokens each internal interaction consumes. Certain workflow steps or even the system overall may be operating in highly token-inefficient ways. Since excess token usage impacts both cost and performance, tracking tokens at a granular level helps us identify exactly where optimizations are necessary and quantify the impact different optimizations will have.
Model drift metrics track instances where the model deviates from expected behavior by tracking changes in a combination of variables (e.g., drops in response quality, increases in latency, spikes in token consumption, inconsistent resource utilization). Often, nothing seems to “break” immediately, but performance gradually erodes over time.
Where Is Observability Implemented
AI observability tools can be integrated across the entire AI stack. Each layer of the stack contains different information. Depending on what your solution is designed to do and what your performance goals are, you will need to collect observability data across one or more of these layers.
Observability tools can track different signals at each layer of the AI system:
At the model layer, they track model-specific signals (e.g., prompt/response pairs, chain-of-thought, token usage, latency). This data can reveal the performance impact of changing the models used in the system or implementing the models in different ways.
At the application layer, they track user interactions with AI features. This data can reveal how much each feature is actually being used and the resulting impact on core business metrics (e.g., daily active users, conversion rates, user satisfaction).
At the orchestration layer, they track how well the system is managing internal operations (e.g., LLM calls, tool selection, decision logic). This data can reveal which failures lead to problems downstream.
At the agentic layer, they track how different variables influence the agent’s output (e.g., reasoning chains, memory, tool usage, intermediate outputs). Agentic systems must handle multi-step reasoning, while potentially coordinating multiple agents, so this data can reveal how failures compound across steps.
At the semantic search and vector database layer, they track information retrieval-specific signals (e.g., embedding quality, retrieval relevance scores, query latency). In certain domains, experts may need this data to assess whether the retrieved information was actually relevant.
At the infrastructure layer, they track how AI operations impact the underlying infrastructure (e.g., GPU utilization, memory pressure, network bottlenecks, inference costs). This data can reveal how the system performs at scale and varying loads. It can also help in evaluating whether an external cloud provider is meeting the system’s needs.
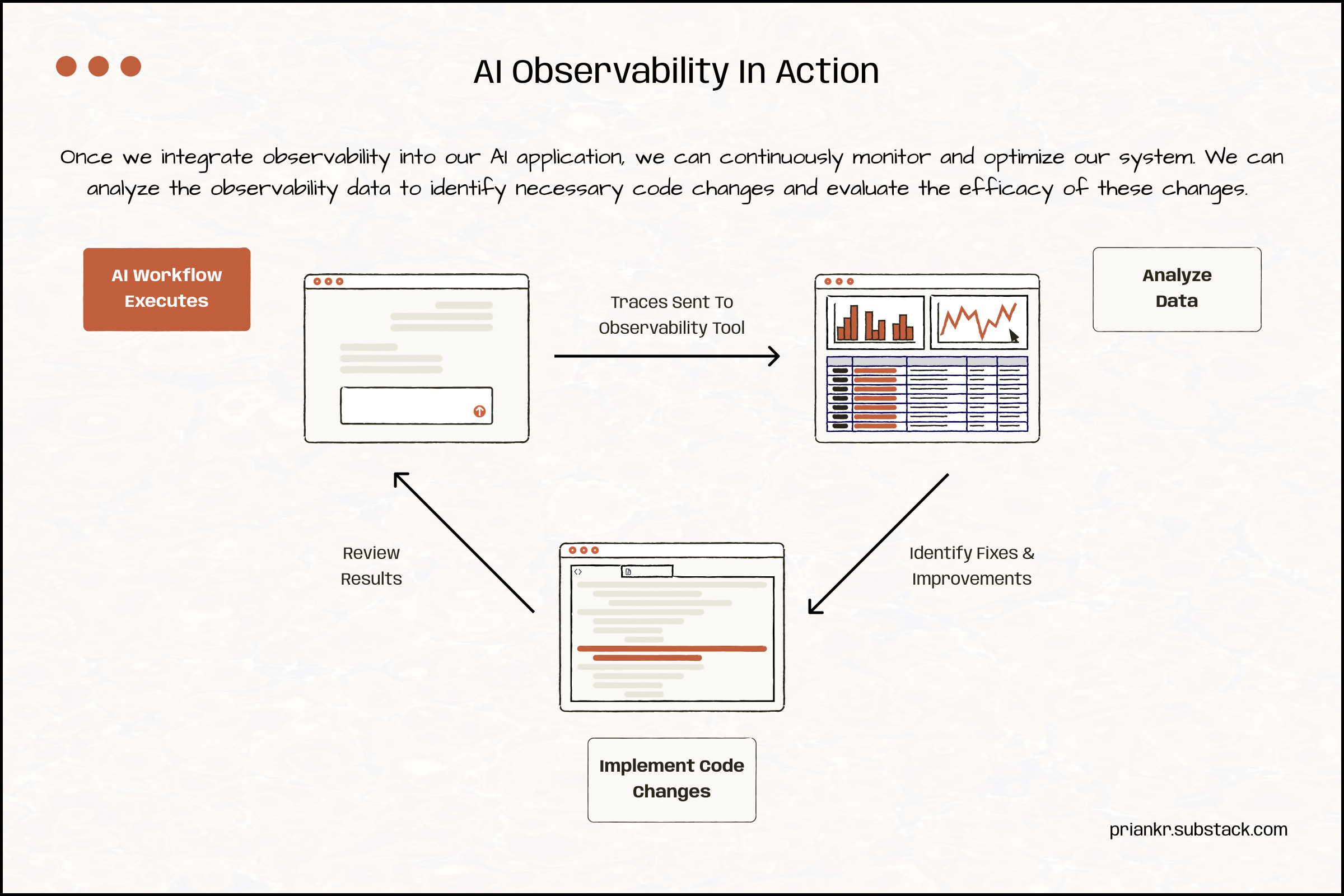
Why Observability Matters
It can be instrumental in making AI systems more robust and reliable.
Observability data can help developers debug, optimize, and improve AI solutions, since it provides real-time visibility into every layer of the system. If performance and output quality are going up or down, the data can reveal what is going wrong and why. Visibility becomes essential in critical workflows. For example, if an agent produced a bad output, the data helps us trace workflows from end-to-end, so we can identify where a specific failure originated (e.g., prompt, data sources, tool selection). Without observability, it can take engineers 5-10 times longer to investigate issues. This means teams spend more time firefighting than shipping new features or improvements. Similarly, they can use observability data to identify inefficiencies and test different optimization strategies.
It offers key benefits for production AI systems:
Improved cost control: It gives us greater insight into how cost-intensive each step of a workflow is, helping us attribute cost to specific choices (e.g., user behavior, model selected, tool used, system prompt provided).
Better failure analysis: It helps us flag failure modes early (e.g., latency spikes, tool failures, hallucinations, poor retrieval). It also accelerates the debugging process since we can see exactly where a failure originated.
Enhanced quality control: It allows us to evaluate the quality of both the process and outputs, so we can track whether model performance is improving or degrading based on the changes we are implementing.
Teams investing heavily in observability often see both an increase in reliability and in incidents. While this may be alarming for executives, they need to recognize they are not seeing new problems. They are just spotting existing ones that have gone undetected.
“The goal isn’t zero incidents detected—it’s zero incidents that reach production without your knowledge. A team detecting 100 issues internally and resolving them before deployment is far healthier than a team detecting 10 issues while customers encounter the other 90.”
— John Weiler, Backend Engineer at Galileo AI
It is especially critical in agentic systems.
You shouldn’t be deploying AI agents in production environments without observability. The very capabilities that make agents valuable also make them difficult to monitor, understand, and control. Surveys indicate that 45% of executives see the lack of visibility into agent decision-making processes as an implementation barrier. Since it can be hard to understand the agent’s reasoning and actions, there’s a risk of compliance violations, operational failures, and loss of user trust. The risk is even greater with multi-agent systems, where failures can be much harder to evaluate. Observability data can reveal the why behind agent decisions, providing visibility into every phase of the agentic workflow.
It is necessary when using models from external providers.
Most AI solutions integrate models from external providers. However, these providers can make changes that negatively impact your system. For example, they may deprecate a model that’s been working well for you. Simply switching to the newer version won’t always lead to better or even similar performance. For example, GPT 5.5 is actually worse than GPT 5.4 at some general-purpose tasks. The switch may help in some workflows and hurt in others. You will need observability data to adapt to provider-side changes. Without it, you have no way to fully evaluate the performance gap in affected workflows. Since many harness optimizations and guardrails can also become ineffective when you change models, we need observability data to understand the specific switching costs.
Why Observability Is Essential For Reliable AI Systems
It won’t matter if your AI solution produces great results sometimes, or even most of the time, if its failures keep hurting your customers and your business. Observability data lets us validate that the system is doing what it’s supposed to, and spot problems fast when it’s not.
It helps us implement evaluations that ensure the system actually works.
Observability data can help us analyze both the process and the output in real time. We can use observability tools to implement AI evaluations (AI evals), which are structured tests designed around specific performance metrics (e.g., quality scores, retrieval accuracy, token consumption). Evals can help us understand exactly when, where, how, and why the system fails, as well as the frequency and severity of those failures. This can help us design better architectural constraints to manage these issues and optimize the system’s behavior. Without evals, you have no way to objectively verify whether you’re getting good results and whether the cost and performance tradeoffs are worth it.

It helps us detect the issues our system guardrails miss.
Observability data can help us verify whether AI systems are operating safely and securely. The guardrails we implement can’t fully eliminate risks. They may handle most issues, but they won’t stop all of them. Therefore, we need robust monitoring systems to flag those that get through. We can use observability tools to track potential system failures (e.g., sensitive data leaks, unauthorized processes, harmful actions). This can also help in detecting user misuse (intentional or unintentional). When unusual patterns are detected, we can trigger alerts or automatic responses (e.g., stop the workflow, require user confirmation, flag the user’s account). Developers can also analyze observability data to discover new vulnerabilities and misuse patterns, so they can fix or improve existing guardrails as needed.

It makes our system’s behavior more explainable.
Observability data is becoming essential for accountability. As AI systems handle more consequential decisions, both developers and users may want to know why the system behaved in certain ways. Since we can’t fully understand how the underlying models “think,” observability data can help us at least identify all the variables that influenced the system’s reasoning. Emerging regulations (e.g., EU AI Act) now also require you to explain how your system made each decision. For example, if an AI insurance product denied a user’s claim, you may need to provide details explaining the rationale. The level of traceability observability data offers may become essential during inquiries, investigations, and audits, especially as AI solutions are deployed in more critical applications (e.g., healthcare, law, finance).
Getting Started With Observability
Use coding assistance to integrate observability into your system.
AI coding agents can be incredibly helpful in getting your system connected to an observability tool. You can use them to add the code needed to send traces to the tool anytime the system initiates workflows you want to monitor. The agents can walk you through the initial tool setup and help you troubleshoot any issues you encounter. I recommend starting with an open source tool (e.g., Langfuse, PostHog) because these typically have solid documentation and extensive community resources (e.g., forums, discussion threads, articles). They’re also typically free or cheaper compared to proprietary tools (e.g., LangSmith), which is helpful when you’re still experimenting.
Capture at least the bare minimum observability data.
Many AI product builders make the mistake of not prioritizing observability because they’re getting “good” results. You have to monitor your most critical workflows (at least). This is where the unexpected behavior could cause the most harm. For example, if your system generates important artifacts (e.g., reports, presentations, analyses), start tracking basic data across these workflows (e.g., model inputs & outputs, token consumption, tool use). The observability data can reveal answers to several key questions: Is your system prompt detailed enough? Does the model have the right context? Does it use the available tools properly? etc. When you have better visibility, you can examine what’s going on in much more detail and spot the technical issues and optimization opportunities you have been missing.
Keep track of the observability costs to avoid surprises.
AI observability costs can go up if you’re monitoring a large application with many users. Even with a relatively small application, costs can be higher than expected if you’re not vigilant. You have to be especially careful if you’re running any LLM-as-a-Judge evals. Traces can contain a substantial amount of data. The evaluator model must consume all this context each time it analyzes a trace. Token costs can quickly add up if your application generates a large number of traces. For example, if you have an AI feature used 10+ times a day by 100 users, you’re running (and paying for) the eval 1,000+ times daily. You may need to manage costs by minimizing the context, running evals only periodically after major changes, or placing other limits on traces.
Conclusion
AI solutions can seem to work great in demos, testing, and production, while serious issues fester internally. Users may not report any issues, and the system’s outputs may even be genuinely good. However, without observability data, we can’t validate whether everything is actually working well. We may have only avoided serious problems by pure chance, but luck is not a real strategy.
As models get more powerful and AI solutions become more agentic, observability becomes a critical oversight mechanism. The failure modes get subtler, the decision chains get longer, and the consequences of failures become more severe.
Observability doesn’t eliminate all the risks, but it closes the gap between what we assume is happening inside our systems and what’s actually happening. It makes flaws and inefficiencies visible early, so we can act on them before things seriously go wrong. Without observability, we have no way to know whether our solutions are truly reliable.
Thanks For Reading
If you haven’t already, please consider subscribing and sharing this newsletter with a friend. I hope you have a great week!
Key References
Priank’s Newsletter
Galileo AI
IBM
LangChain